
Researches
You can also find my articles on my Google Scholar profile.
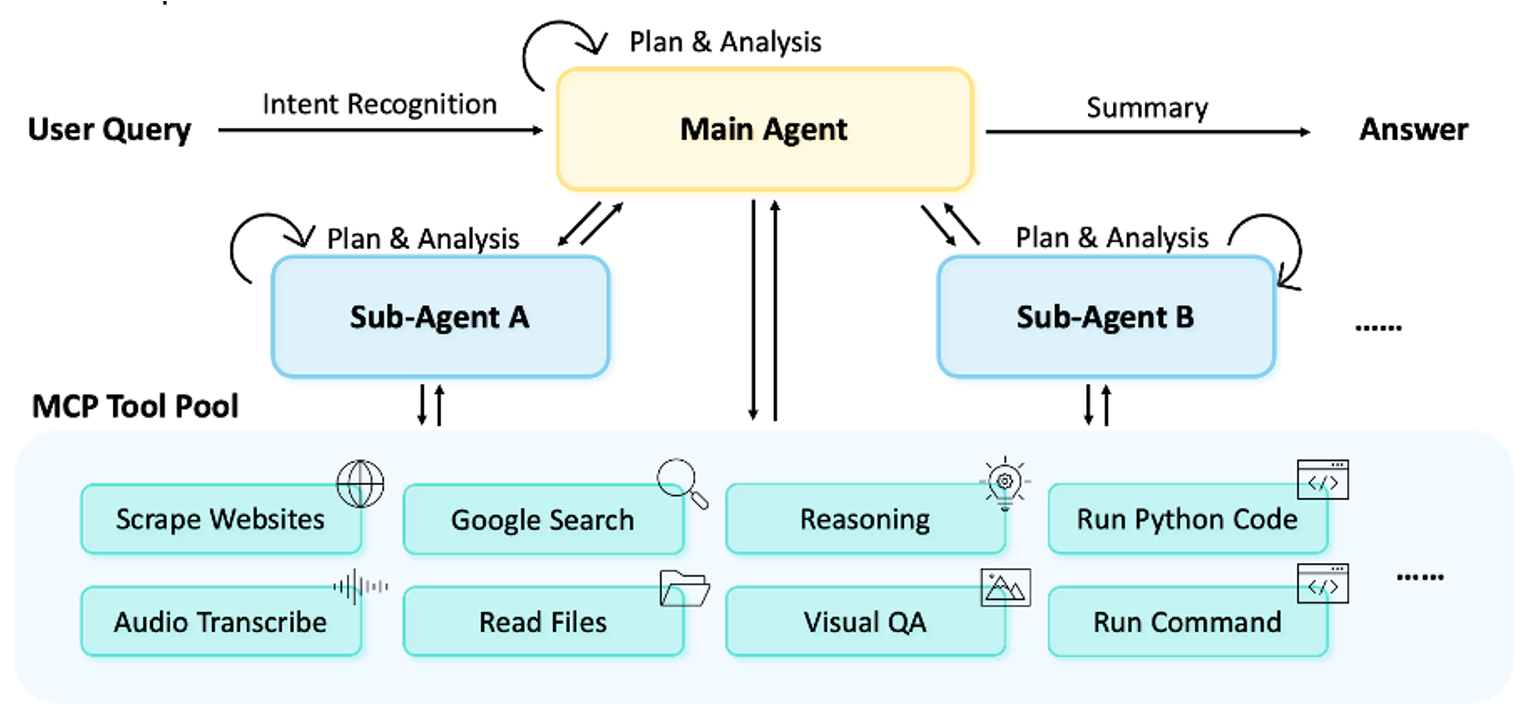
MiroFlow: Towards High-Performance, Robust, and Open-Source Reproducible Agent Framework for General Research Tasks
MiroMind Team, as first core contributorPreprint / Paper / Blog / GitHub / Demo
MiroFlow is a robust open-source agent framework with flexible orchestration and optional deep reasoning. It achieves state-of-the-art results across multiple benchmarks and provides a stable, reproducible baseline for future research.
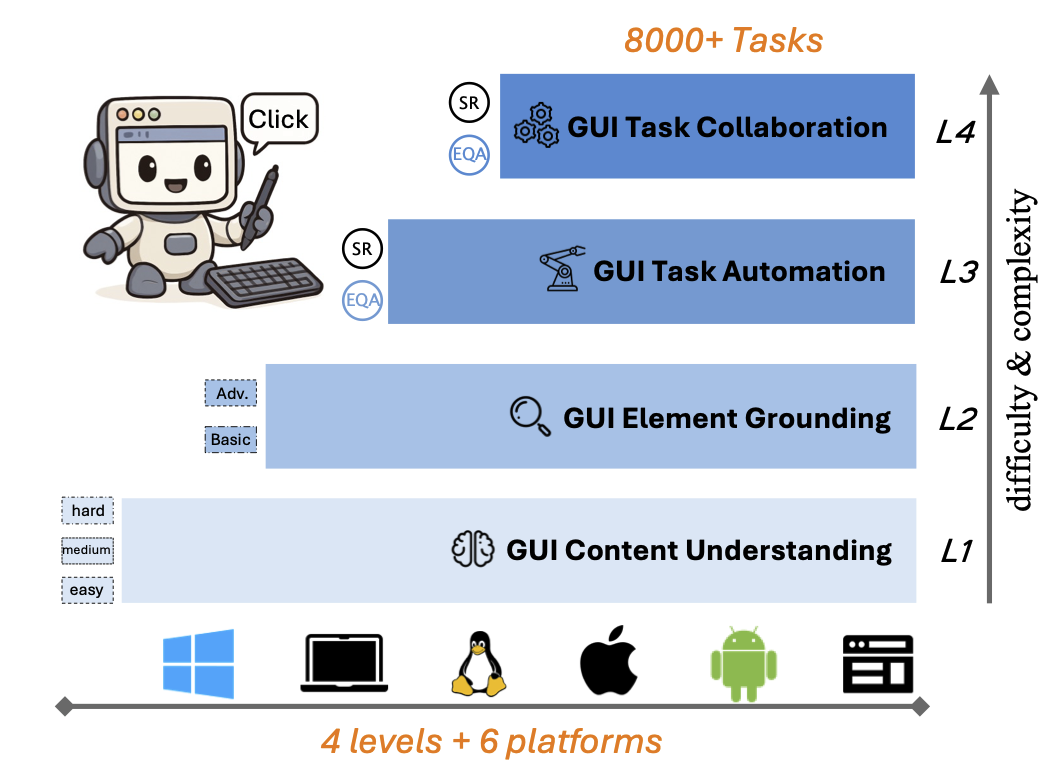
MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents
Wang, X., ..., Su, S., ..., Dai, J., Wang, W.CVPR 2026 / Paper / GitHub
MMBench-GUI is a hierarchical benchmark for GUI automation across six major platforms. It evaluates four essential skills and proposes a new Efficiency-Quality Area metric. Our findings show that precise grounding, solid planning, and cross-platform generalization are crucial for reliable and efficient GUI automation.
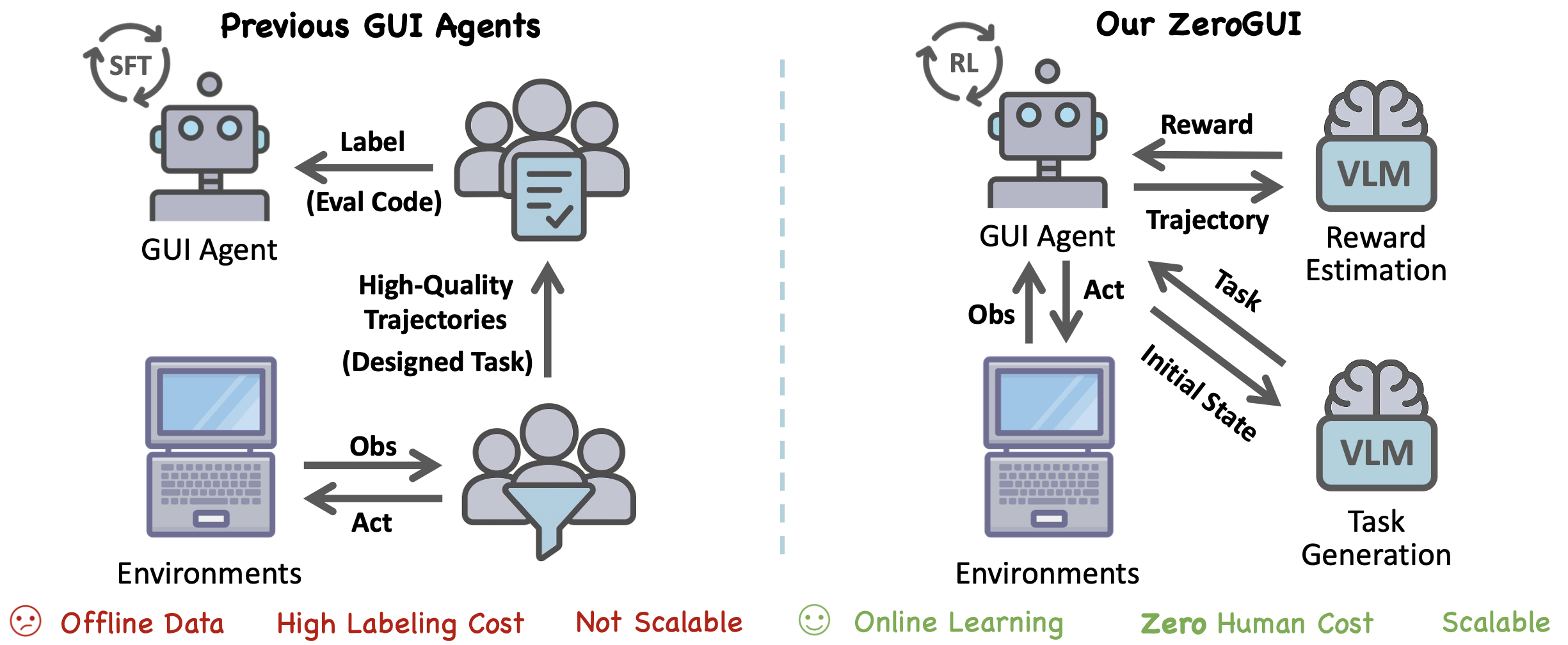
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
Yang, C.*, Su, S.*, Liu, S.*, Dong, X.*, Yu, Y.*, Su, W.*, ... & Dai, J.Preprint / Paper / Model / Code
ZeroGUI is a scalable, online learning framework that trains vision-based GUI Agents without human supervision by using Vision-Language Models (VLMs) for automatic task generation, reward estimation, and reinforcement learning.
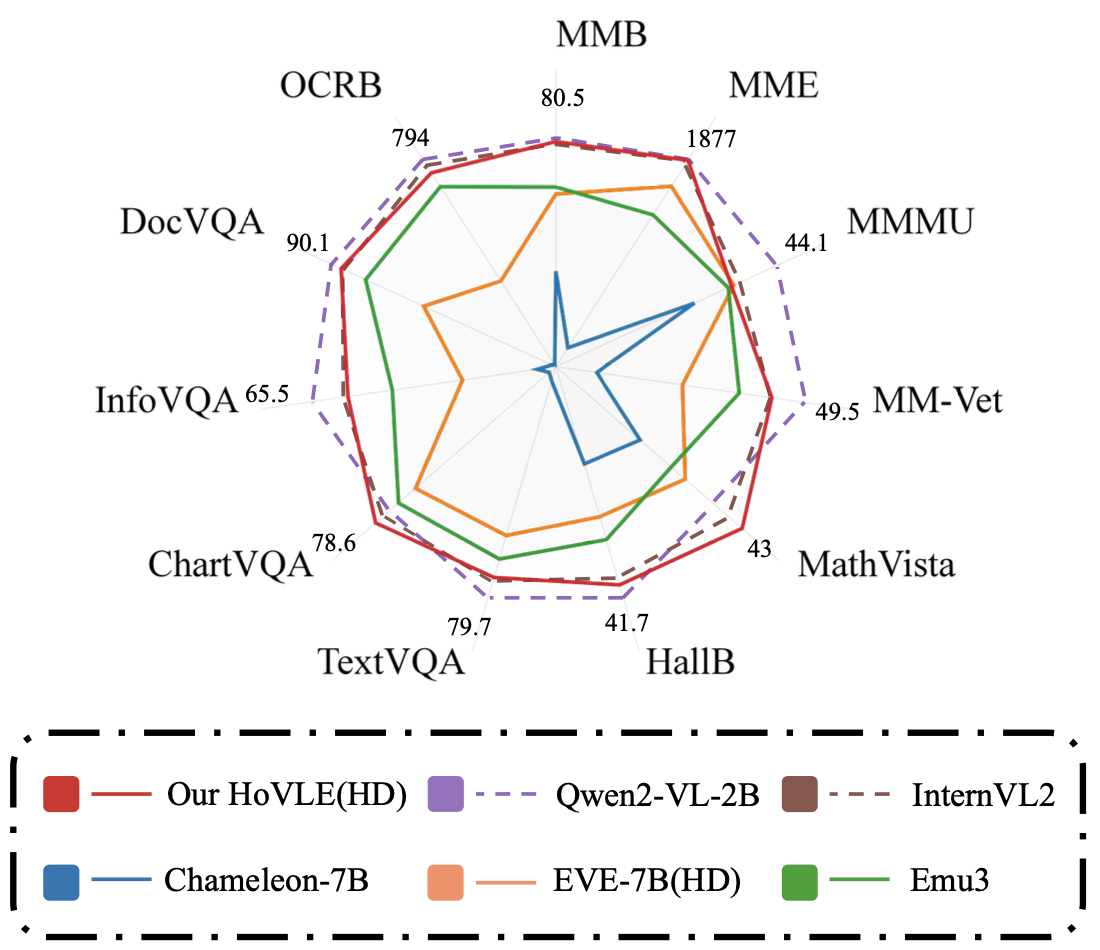
HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding
Tao, C.*, Su, S.*, Zhu, X.*, Zhang, C., Chen, Z., Liu, J., ... & Dai, J.CVPR 2025 / Paper / Model
HoVLE is a high-performance monolithic Vision-Language Model that uses a insightful holistic embedding module to effectively integrate vision and language, outperforming previous models.

Learning 1D Causal Visual Representation with De-focus Attention Networks
Tao, C.*, Zhu, X.*, Su, S.*, Lu, L., Tian, C., Luo, X., ... & Dai, J.NeurIPS 2024 / Paper / Code
De-focus Attention Networks are introduced to address the “over-focus” issue in 1D causal vision models by using several inspiring ideas, enabling 1D causal vision models to match 2D models in performance.